INDEX
1. Introduction
- Two key components in learnable CF models
- embedding
- interaction modeling
- MF directly embed user/item ID as an vector and models user-item interaction with inner product.
- 저자들은 이런 기존의 방법이, embeddings for CF 를 산출하는 데에는 부족하다고 주장함
- key reason is that the embedding functions lacks an explicit encoding of the crucial CF signal
- CF signal?? - latent in user-item interactions to reveal the behavorial similarity between users/items.
- 말 그대로 협업 필터링에 사용되는 정보
- NGCF 이전에는 embedding 이후, interaction 의 reconstruction 을 학습하는 과정에서 이런 CF signal 이 implicit 하게 embedding 에 반영되는 형식이었음 - only used to define the objective function for model training
when the embeddings are insufficient in capturing CF, the methods have to rely on the interaction function to make up for the deficiency of suboptimal embeddings- 당연한 거 아닌가?
- directly embedding 은 직관적이고 쉽지만, 잘 작동한다는 보장이 없다 (non-trivial to do it well)
- 특히 real application 에서는 user-item interaction이 millions or even larger 될 수 있고, 이는 CF signal 을 증류(distill ~ extract)하는 데에 어려움을 줄 수 있음.
- 이 논문에서는 user-item interaction에서 high-order connectivity(이하 HC) 를 exploit 하는 방법론을 제시한다. interaction graph structure 를 사용해서
Running Example

- The user of interest for recommendation is $u_1$.
$u_1$ 을 기준으로 확장된 tree 구조 (오른쪽) - HC 는 $u_1$ 에서 시작된, path length 가 1 보다 큰 path 들을 의미한다. 이들은 더 고차원적인(rich semantics) CF signal 을 갖는다.
- The path $u_1 \leftarrow i_2 \leftarrow u_2$ indicates the behavior similarty between $u_1$ and $u_2$
- $u_1 \leftarrow i_2 \leftarrow u_2 \leftarrow i_4$ 는 $u_1$ 과 $i_4$ 의 관계를 나타낼 수 있다
- $l=3$ 인 경우에서 $i_5$ 와 연결된 path 보다 $i_4$ 와 연결된 것이 더 많고, 이 정보를 $u_1$ 의 embedding 에 주입(inject)할 수 있다.
Present Work
- interaction graph 를 tree 형식으로 확장하는 것은 구현하기에 복잡하다
- graph 위에서 embedding 을 재귀적으로 전파(propagate)시킬 수 있는 neural netowrk 를 디자인했다고 함 (gnn 에서 영감)
- embedding propagation layer (이하 EP)
- can be seen as constructing information flows in the embedding space
- embedding space?
- EP 를 계속 쌓으면서 HC 를 포착할 수 있다.
- 위 사진의 경우, EP 를 2층으로 쌓으면 $u_1 \leftarrow i_2 \leftarrow u_2$ 를, 3층으로 쌓으면 $u_1 \leftarrow i_2 \leftarrow u_2 \leftarrow i_4$ 의 정보(behavoir similarity, CF signal, HC)를 포착할 수 있다.
- graph 위에서 embedding 을 재귀적으로 전파(propagate)시킬 수 있는 neural netowrk 를 디자인했다고 함 (gnn 에서 영감)
Main Contributions
- model-based CF 의 embedding function 에서 CF signal 을 explicit 하게 exploit(inject, 사용, 주입) 하는 것의 중요성을 강조함
- HC 로써 드러나는 CF signal 을 explicitly encode 할 수 있는 추천 프레임워크 NGCF 제안
- sota
2. Methodology
- Initialization of user/item embeddings
- Multiple embedding propagation layers - injecting HC to refine the embeddings
- prediction
- aggregates the refined embeddings from defferent propagation layers
- outputs the affinity score of a user-item pair (inner product)
2.1 Initialization of user/item embeddings
-
\[\text E = [ \ \underbrace{e_{u_1}, \cdots, e_{u_N}}_{\text{users embeddings}}, \underbrace{e_{i_1}, \cdots, e_{i_M}}_{\text{items embeddings}} ] \tag{1}\]
- $e_u \in \mathbb R^d$, $d$ denotes the embedding size
- pytorch 의 lightgcn 에서도 이런 식으로 구현함
- traditional recommender model (MF, NCF 등) 에서는 이 ID embeddings 가 interaction layer 혹은 operation(inner product) 에 그대로 들어갔다.
- ngcf 에서는 user-item interaction graph 에서 정보들이 전파되면서 embedding 을 refine 하는 과정을 거친다
- 이런 embedding refinement step 을 통해 CF sifnal 을 embedding 에 explicitly inject 할 수 있다
2.2 Embedding Propatation Layers
2.2.1 First-Order Propagation
- 직관적으로, 어떤 user 와 interact 된 item 은 user 의 preference 에 대한 직접적인 증거(evidence)이다
- 반대로 item 의 입장에서 그것을 사용한 user 는, 그 item 의 feature 로써 사용될 수 있고 두 아이템 간의 collaborative similarity 를 표현할 수도 있다
- 이런 basis 에서 EP 는 이루어지고, EP 는 message construction 과 message aggregation 으로 이뤄진다
- EP가 쌓이면 message construction 과 aggregation 이 재귀적으로 이뤄진다
- Message Construction
- user-item pair $(u, i)$
- message from $i$ to $u$ as:
- \[\text m_{u \leftarrow i} = f(\text e_i, \text e_u, p_{ui})= \frac{1}{\sqrt{\lvert\mathcal N_u\rvert\lvert\mathcal N_i\rvert}}\left(\text W_1\text e_i + \text W_2\left(\text e_i \odot \text e_u \right)\right) \tag{2, 3}\]
- $m_{u \leftarrow i}$ 는 전파되는 정보(message embedding, information to be propagated)이고, $f(\cdot)$ 은 message encoding function($\text e_u$, $\text e_i$ 가 입력)이다. $p_{ui}$ 는 정규화 상수(decay factor)이다
- $\text W_1, \text W_2 \in \mathbb R^{d’ \times d}$ are the trainable weight matrices to distill useful infomation for propagation
- $\text e_i$ 의 contribution 이외에도, $\text e_u$ 와 $\text e_i$ 의 interation 을 반영했다는 것이 conventional GCN 과의 차이이다
- 이는 message 가 $\text e_i$ 와 $\text e_u$ 의 affinity 에 의존적이게 한다
- 이는 model의 representation ability 와, 추천 성능을 상승시킨다
- 4.4.2
- $p_{ui} = \frac{1}{\sqrt{\lvert\mathcal N_u\rvert\lvert\mathcal N_i\rvert}}$ 는 graph Laplacian norm 이고, $\lvert\mathcal N_u\rvert$, $\lvert\mathcal N_i\rvert$ 는 first-hop neighbors of user u and item i 이다.
- representation learning 의 관점에서 이것은, 각 item 들이 user preference 에 얼마나 반영되는지를 나타낸다
- user 가 사용한 item 의 개수에 embedding 이 영향 받지 않도록 해주는 것 같다
- message passing 의 관점에서 이는 discount factor 이다. path length 가 길어질수록 propagating 되는 message 는 decay 되어갈 것이다
- representation learning 의 관점에서 이것은, 각 item 들이 user preference 에 얼마나 반영되는지를 나타낸다
- Message Aggregation
- aggregate the messages propgated from $u$’s neighborhood to refine $u$’s representation
-
\[\text e_u^{(1)} = \text{LeakyReLU}\left(\text m_{u \leftarrow u} + \sum_{i \in \mathcal N_u} \text m_{u \leftarrow i}\right) \tag{4}\]
- $\text e_u^{(1)}$ 에서 (1) 은 첫 번째 propagation layer 에서 나온 embedding 이라는 의미이다
- 주목해야 할 부분은 다음과 같다
- activation function
- $u$ 의 이웃들인 $\mathcal N_u$의 정보뿐만 아니라 $\text m_{u \leftarrow u}$ 로써 나타나는 self-connection 정보도 전파된다 (이 정도 또한 고려한다 - into consieration)
- 이때 $\text m_{u \leftarrow u} = \text W_1 \text e_u$ 이다.
- To summarize, the advantage of the embedding propagation layer lies in explicitly exploiting the first-order connectivity information to relate user and item representations.
2.2.2 High-Order Propagation
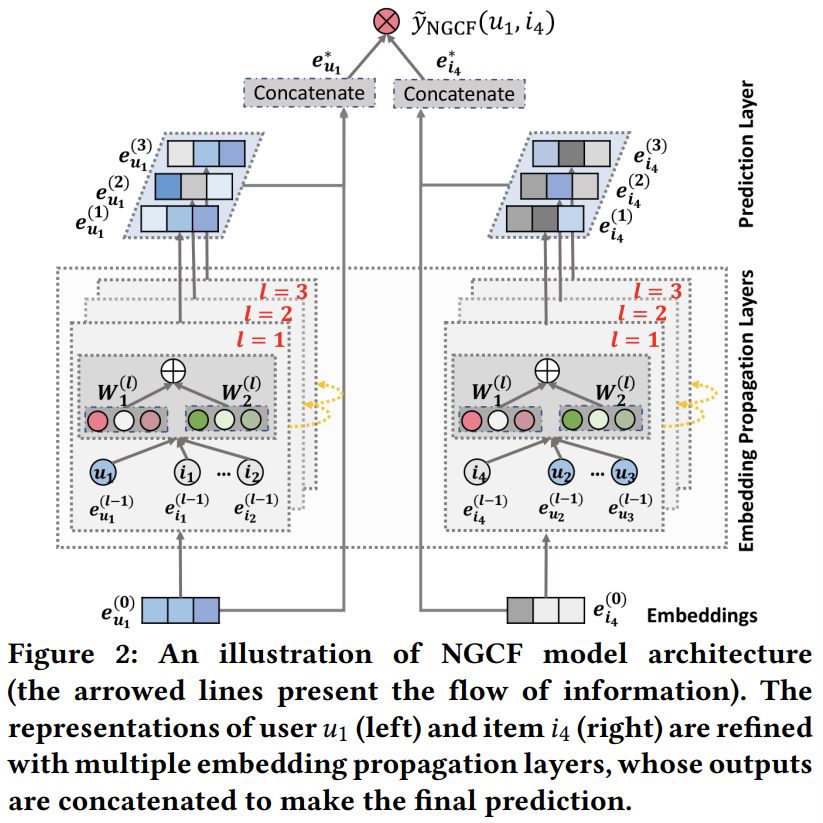
- We can stack more embedding propagation leyers to explore HC information.
- Fig 2에서 표현된 것처럼, $l$-th step 에서 user $u$ 의 representation 은 재귀적으로 구해진다:
\(\text e_u^{(l)} = \text{LeakyReLU}\left(\text m_{u \leftarrow u}^{(l)} + \sum_{i \in \mathcal N_u} \text m_{u \leftarrow i}^{(l)}\right) \tag{5}\) - 그리고 이때 construct 되는 message 들은 다음과 같다
-
\[\begin{cases} \text m_{u \leftarrow i}^{(l)} = \left(\text W_1^{(l)}\text e_i^{(l-1)} + \text W_2^{(l)}\left(\text e_i^{(l-1)} \odot \text e_u^{(l-1)} \right)\right),\\ \text m_{u \leftarrow u}^{(l)} = \text W_1^{(l)}\text e_u^{(l-1)} \end{cases} \tag{6}\]
- 이때 $\text W_1^{(l)}, \text W_2^{(l)} \in \mathbb R^ {d_l \times d_{l-1}}$ 이다.
- $\text e_i^{(l-1)}$ 는 이전 message-passing step 에서 생성된 item representation 이다
- ($l$-1)-hop neighbors 들의 message 들을 함축하고(memorizing) 있다고 볼 수 있다.
- 이미 있는 정보($l$-1 번째 embedidng)에 새로운 정보($l$ 번째 이웃의 정보) 를 계속해서 추가하는, 그런 식으로 업데이트해 나가는 - 일종의 DP(memoization)으로 볼 수도 있을 것이다
- 이를 통해 $l$ 번째 layer 의 representation 을 얻을 수 있다

- Fig 3 에서 CF signal 이 어떤 방식으로 전파되는지 나와있다
- 빨간색으로 칠해진 경로를 보면, $i_4$ 로부터의 message 가 $\text e_{u_1}^{(3)}$ 로 explicitly encode 된다
- EP layer 를 쌓는 것은 매끄럽게(seamlessly) CF signal 을 representation learning process 에 주입(inject) 시킬 수 있다
- Propagation Rule in Matrix Form
- EP 를 holistic 한 관점에서 보기 위해, 그리고 batch implementation 을 가능케 하기 위해 matrix form of the layer-wise propagation rule 은 필요하다
- 식은 다음과 같다 (식 (5), (6)과 동일한 의미를 가진다)
-
\[\text E^{(l)} = \text{LeaklyReLU}\left(\left(\mathcal L + \text I\right)\text E^{(l-1)} \text W_1^{(l)} + \mathcal L \text E^{(l-1)} \odot \text E^{(l-1)} \text W_2^{(l)}\right) \tag{7}\]
- $\text E^{(l)} \in \mathbb R^{(\text N+ \text M) \times d_l}$ are the representations for users and items obtained after $l$ steps of embedding propagation
- $l$ 번째 layer 의 embedding 들이다. 여기서 $\text N$ 과 $\text M$ 은 각각 user 와 item 의 개수를 나타낸다. (혹은 item 과 user. 구현하기 나름)
- 식 (5), (6)은 재귀적으로 계산되는 반면, 이 matrix form 에서는 그런 게 없다. 단순 for loop 로 구현할 수 있을 것이다
- laplacian matrix 를 사용해 한 번에 모든 embedding 들을 일괄적으로 업데이트하기 때문이다
- $\mathcal L$ 은 laplacian matrix 이다. 다만 일반적인 정의와는 좀 다른데:
-
\[\mathcal L = \text D^{-\frac{1}{2}}\text A \text D^{-\frac{1}{2}}, \ \ \text A=\left[\begin{matrix}0 & \text R\\ \text R^\intercal & 0\\ \end{matrix}\right] \tag8\]
- 여기서 $\text R \in \mathbb R^{\text N \times \text M}$ 이고 user-item interaction matrix 를 나타낸다
- $0$ 은 영행렬을 나타낸다
- $D$ 는 degree matrix 이다 ($D_{tt} = \lvert\mathcal N_t\rvert$)
- 따라서 $\mathcal L$ 의 nonzero off-diagonal entry $\mathcal L_{ui}$ 는 $\frac{1}{\sqrt{\lvert\mathcal N_u\rvert\lvert\mathcal N_i\rvert}}$ 이고, 이는 식 (3) 의 $p_{ui}$ 와 같다
-
\[\mathcal L = \text D^{-\frac{1}{2}}\text A \text D^{-\frac{1}{2}}, \ \ \text A=\left[\begin{matrix}0 & \text R\\ \text R^\intercal & 0\\ \end{matrix}\right] \tag8\]
- $\text I$ 는 identity matrix 이고, 이는 (4) 식에서 언급된 self-connection 을 위해 존재한다
- $\text E^{(l)} \in \mathbb R^{(\text N+ \text M) \times d_l}$ are the representations for users and items obtained after $l$ steps of embedding propagation
- 이 matrix form 을 사용하면 한 번에(simultaneously) 모든 user, item 들의 embedding 을 보다 효율적인 방식으로(rather efficient way) 업데이트시킬 수 있다
- 처음 이 문장을 보고, 저렇게 모든 임베딩들을 업데이트해도 어차피 우리가 쓰는 임베딩은 한정되어있을 텐데, 정말 더 효율적인지에 대한 의문이 있었다 - 다 쓸 것도 아닌데 왜 다 업데이트하는가?
- 아래 사진은 CS224W 의 7강에서 나온 사진이다.
$l$ 이 3만 돼도 대부분의 node 가 겹치는 걸 볼 수 있다
$l$ 이 커질수록 겹치는 node 는 많아질 것이고, 여기서 batch size 가 커지면 겹치는 node 들은 더 많아질 것이다. 따라서 일일이 하나씩 계산하는 것보다, matrix form 으로 일괄적으로 전부 계산해놓고 사용하는 것이 더 효율적일 것이라는 생각도 든다

- 무엇보다, matrix form 을 사용하면 일괄적인 처리가 가능하다. 식 (5), (6) 으로 업데이트한다면 각 user-item interaction 마다 다른 계산을 해야 한다 - $\mathcal N_u$, $\mathcal N_i$가 서로 다르기 때문이다. 이는 병렬 처리를 어렵게 만들고, matrix form 이 아니기 때문에 일괄적인 처리도 어렵다 - 재귀적으로 연산해야 함
- RNN 과 transformer 를 병렬 처리의 측면에서 비교했을 때의 차이로 빗대어 표현할 수 있을 것이다. RNN 은 병렬 처리가 불가능하고, transfromer 는 가능하다. RNN 이 병렬 처리를 할 수 없는 이유와 식 (5), (6)에서 불가능한 이유가 다르긴 하지만 아무튼..
- 논문에서는
It allows us to discard the node sampling procedure, which is commonly used to make graph convolution network runnable on large-scale graph
라고 표현하는데, GCN 논문을 아직 읽지 않아 잘 모르겠음. node sampling procedure? 위에서 언급한 재귀적인 방법을 의미하는 것인가? - 각 user, item 의 이웃을 일일이 sampling 하는?
2.3 Model Prediction
- $L$ 개의 layer 를 전부 통과한 뒤, 우린 the user of interest for recommendation 의 embedding 을 $L$ 개 얻을 수 있다. Namely, ${\text e_u^{(1)}, \cdots \text e_u^{(L)}}$
- 이렇게 생성된 embedding 들을 concat 하는 것은 합리적인 방법이다
- \[\text e_u^*=\text e_u^{(0)}\lVert\cdots\rVert \text e_u^{(L)}, \ \ \text e_i^*=\text e_i^{(0)}\lVert\cdots\rVert \text e_i^{(L)} \tag9\]
- $L$ 을 조정하면서 변화를 관찰하기 쉽다 - concat 만을 하기에 외부 요인이 없음
- 간단하다!
- No additional params
- ‘Representation Learning on Graphs with Jumping Knowledge Networks’ 이라는 논문에서 이런 concatenation 이 꽤 효과적이라는 게 보여졌다고 함
- 안 읽어봐서 잘 모르겠음
- 물론 concat 하지 않고 weighted sum 이나 avarage 를 구하든지 아니면 LSTM 에 태우는 것도 가능하다 - 이런 방법론들은 concat 과는 달리 어떤 assumption 들을 내포하고 있다고 봐야 할 것이다
- 이후 내적으로 결과를 구하게 된다
- \[\hat y_{\text{NGCF}}(u, i) = {\text e_u^*}^\intercal \text e_u^* \tag{10}\]
- interaction function 으로는 당연히 내적 이외에 NCF 나 기타 다른 방법론을 써도 될 것이다
- DKT 같은 task 의 경우엔 이렇게 나온 embedding 을 LSTM 이나 BERT 등에 그대로 넣어 활용하는 방법도 가능할 것 같다
- end2end 로 학습? 아니면 따로?
3. Conclusion
- Explicitly incorporate collaborative signal into the embedding function
- CF signal 을 embedding function 에 명시적으로(explicitly) 포함시켰다
- Leverage high-order connectivities in the user-item integration graph
- user-item integration graph 의 HC 를 활용한다
- Inject the user-item graph structure into the embedding learning process
- user-item graph structure 를 임베딩 과정에서 활용한다
- Exploit structural knowledge with the message-passing mechanism
- 3번 내용과 일치함. 그래프 구조를 활용한다는 의미
- Further study
- Improve NGCF by incorporating the attention mechanism
- To learn variable weights for neighbors during embedding propagation and for the connectivities of different orders
- 이게 이유라고 하는데.. connectivities of different orders 을 학습한다는 게 정확히 무슨 의미인지 모르겠다. neighbor 들끼리 attention value 를 계산한다는 거 아닌가? 갑자기 different orders 가 왜 나오지?
- Exploring the adversarial learning on user/item embedding and the graph structure for enhancing the robustness of NGCF
by integrating item knowledge graph with user-item graph, we can establish knowledge-aware connectivities between users and items- item knowledge graph 가 뭔지 몰라서 해석 불가
- Improve NGCF by incorporating the attention mechanism
2.4 에서는 loss function(BPR임), model size, dropout 기법들(message dropout, node dropout), SVD++와의 비교, 시간복잡도를 다룬다. chap 3은 related work, 4는 experiment 이다.
이 내용들은 NGCF 를 이해하는 데에 그리 중요한 내용은 아니라 생각해 생략했음
first draft: 2022.12.02 02:53